Variational Bayes and the evidence lower bound
by benmoran
Variational methods for Bayesian inference have been enjoying a renaissance recently in machine learning.
Problem: normalization can be intractable when applying Bayes’ Theorem
Given a likelihood function and a prior distribution that we can evaluate, 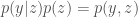
The posterior is just 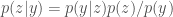

![p(y) = \int p(y\vert z) p(z) dz = \mathbb{E}_{p(z)}[p(y\vert z)]](https://s0.wp.com/latex.php?latex=p%28y%29+%3D+%5Cint+p%28y%5Cvert+z%29+p%28z%29+dz+%3D+%5Cmathbb%7BE%7D_%7Bp%28z%29%7D%5Bp%28y%5Cvert+z%29%5D&bg=fff&fg=444444&s=0&c=20201002)
However, 
Here are three techniques we can use to approach it:
- If the posterior
and prior
are of particular forms so that they are conjugate to one another, then the integral will have a simple closed form. Then the updates to the prior from the likelihood are often trivial to calculate.
- It is possible to draw samples from the posterior before we know the normalization factor. Then we can approximate the expectation stochastically by sample averages. By drawing enough samples the expectations converge to the true values – the theory behind MCMC techniques. Two hindrances arise: it is difficult to know how many samples is “enough”; and “enough samples” can also take a long time to generate.
- We can introduce an approximating distribution
. If we can somehow measure the quality of the approximation and iteratively improve it as far as possible, we can use this approximation with confidence. This is the variational approach derived below.
Variational lower bound
Start with the KL from 
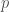

![= \mathbb{E}_{q(z)}[\log q(z) - \log p(z, y) + \log p(y)] dz](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D_%7Bq%28z%29%7D%5B%5Clog+q%28z%29+-+%5Clog+p%28z%2C+y%29+%2B+%5Clog+p%28y%29%5D+dz&bg=fff&fg=444444&s=0&c=20201002)
But
![D_{KL}(q(z) \Vert p(z \vert y)) = \mathbb{E}_{q(z)}[\log q(z) - \log p(z, y)] + \log p(y)](https://s0.wp.com/latex.php?latex=D_%7BKL%7D%28q%28z%29+%5CVert+p%28z+%5Cvert+y%29%29+%3D+%5Cmathbb%7BE%7D_%7Bq%28z%29%7D%5B%5Clog+q%28z%29+-+%5Clog+p%28z%2C+y%29%5D+%2B+%5Clog+p%28y%29&bg=fff&fg=444444&s=0&c=20201002)
Rearranging, we get
![\log p(y) = D_{KL}(q(z) \Vert p(z \vert y) ) + \mathbb{E}_{q(z)}[\log p(z, y) - \log q(z) ]](https://s0.wp.com/latex.php?latex=%5Clog+p%28y%29+%3D+D_%7BKL%7D%28q%28z%29+%5CVert+p%28z+%5Cvert+y%29+%29+%2B+%5Cmathbb%7BE%7D_%7Bq%28z%29%7D%5B%5Clog+p%28z%2C+y%29+-+%5Clog+q%28z%29+%5D&bg=fff&fg=444444&s=0&c=20201002)
Because we saw previously that 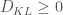
![\log p(y) \geq \mathbb{E}_{q(z)}[\log p(z, y) - \log q(z)] = L[q]](https://s0.wp.com/latex.php?latex=%5Clog+p%28y%29+%5Cgeq+%5Cmathbb%7BE%7D_%7Bq%28z%29%7D%5B%5Clog+p%28z%2C+y%29+-+%5Clog+q%28z%29%5D+%3D+L%5Bq%5D&bg=fff&fg=444444&s=0&c=20201002)
This quantity ![L[q]](https://s0.wp.com/latex.php?latex=L%5Bq%5D&bg=fff&fg=444444&s=0&c=20201002)
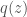
This bound is valuable because it can be calculated without the unknown normalizing constant 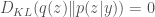
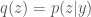
We have transformed the problem of taking expectations into one of optimization. Now a new question arises – is this problem any easier than the integral we started with? Not necessarily! However we can now make different choices for the form of
For example, we can rewrite 
![L[q] = \mathbb{E}_{q(z)}[\log p(y\vert z)p(z) - \log q(z)]](https://s0.wp.com/latex.php?latex=L%5Bq%5D+%3D+%5Cmathbb%7BE%7D_%7Bq%28z%29%7D%5B%5Clog+p%28y%5Cvert+z%29p%28z%29+-+%5Clog+q%28z%29%5D&bg=fff&fg=444444&s=0&c=20201002)
![= \mathbb{E}_{q(z)}[\log p(y\vert z) - \log \frac{q(z)}{p(z)}]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D_%7Bq%28z%29%7D%5B%5Clog+p%28y%5Cvert+z%29+-+%5Clog+%5Cfrac%7Bq%28z%29%7D%7Bp%28z%29%7D%5D&bg=fff&fg=444444&s=0&c=20201002)
![= \mathbb{E}_{q(z)}[\log p(y\vert z) ] - D_{KL}(q(z) \Vert p(z))](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D_%7Bq%28z%29%7D%5B%5Clog+p%28y%5Cvert+z%29+%5D+-+D_%7BKL%7D%28q%28z%29+%5CVert+p%28z%29%29&bg=fff&fg=444444&s=0&c=20201002)
If
(This bound gets its name from the variational principle, applying the calculus of variations to optimize the function

Very nicely explained 🙂
in the beginning p(y,z) should be the joint probability not joint likelihood right? or I am mistaken here
Hi Mohamed. You’re right that p(x, y) is the joint probability density. I’m being sloppy to call it this quantity the likelihood when we’re not considering it as a function of the parameters, e.g. .
.
nice post, man
Cool. You say ‘we replace expectations by optimization’. In my own mind, I see it more like ‘replace marginalization/integration, over all z, by expectation’. Thoughts?
Hi Hugh, you’re right that we could have said “replace integration/marginalization by optimization”. But it’s also true that the quantity we’re trying to calculate is an expectation:![p(y) = \int dz p(y\vert z) p(z) = \mathbb{E}_{p(z)}\left[p(y\vert z)\right]](https://s0.wp.com/latex.php?latex=p%28y%29+%3D+%5Cint+dz+p%28y%5Cvert+z%29+p%28z%29+%3D+%5Cmathbb%7BE%7D_%7Bp%28z%29%7D%5Cleft%5Bp%28y%5Cvert+z%29%5Cright%5D&bg=fff&fg=444444&s=0&c=20201002) . The central problem is always estimating the normalizing constant, but we can choose to solve it in three different ways.
. The central problem is always estimating the normalizing constant, but we can choose to solve it in three different ways.
– Calculate the integral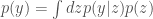 analytically,
analytically,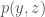 and use empirical averages of the sample to approximate any expectation we want,
and use empirical averages of the sample to approximate any expectation we want,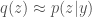 .
.
– Use Monte Carlo to sample from
– Or use variational methods to optimize an approximation
Thank you for the nice post.
I have some minor questions regarding the approximation of the posterior p(y|z).
How do we approximate a conditional probability p(y|z) which should in fact be some function of (y, z) by a single variable function q(z)? I am somewhat confused about this part. Any comments? Thanks!
Hi Daniel. Interesting question!
The *posterior* distribution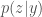 is a distribution over
is a distribution over  alone, once we have conditioned on the observed data
alone, once we have conditioned on the observed data 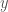 . And
. And 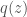 is also a distribution over
is also a distribution over  . So after fixing the value of
. So after fixing the value of 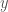 , it does make sense to compare these two distributions over
, it does make sense to compare these two distributions over  , and ask about the divergence between them.
, and ask about the divergence between them.
The *joint* distribution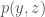 on the other hand is a bivariate distribution over all the possible values of
on the other hand is a bivariate distribution over all the possible values of 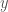 and
and  together.
together.
Why is the integral intractable p(y).
Actually never mind – solved.
Thank you so much for explaining how $L$ can be rewritten as a KL between approximate posterior and the prior over the latent variables.