Kullback-Leibler divergence asymmetry
by benmoran
It’s widely known that the KL divergence is not symmetric, i.e.
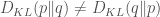
But what’s the intuitive picture of how the symmetry fails? Recently I saw Will Penny explain this (at the Free Energy Principle workshop, of which hopefully more later). I am going to “borrow” very liberally from his talk. I think he also mentioned that he was using slides from Chris Bishop’s book, so this material might be well known from there (I haven’t read it).
f <- function(x) { dnorm(x, mean=0, sd=0.5) }; g <- function(x) { dnorm(x, mean=3, sd=2) }; curve(f(x),-6,6, col="red", ylim=c(-1,1)); curve(g(x),-6,6, col="blue", add=T); scale <- 0.05; curve( scale*(log(f(x))-log(g(x))),-6,6, col="red", lty=3, add=T); curve( scale*(log(g(x))-log(f(x))),-6,6, col="blue", lty=3, add=T);
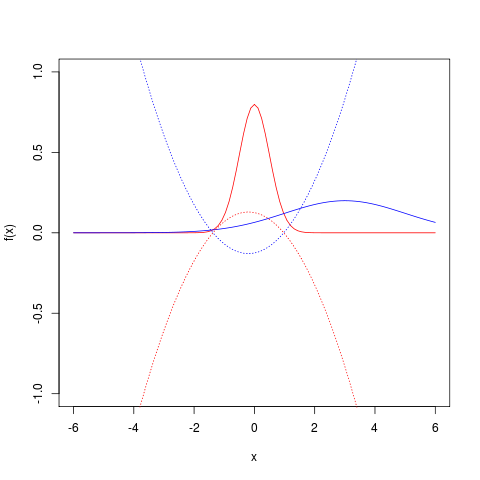
The plot shows two Gaussians, a lower variance distribution 

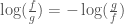
The KL divergence 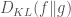

- The KL from
- The quantity inside the expectations, the difference of logs, is actually anti-symmetric. (Somehow it’s remarkable that we can take two differently positively weighted sums of the same quantity with and without a minus sign, but always guarantee a positive result, since
!)
Consequences for optimization
Say we have a multi-modal distribution 
mu1 <- 4.0; sd1 <- 0.8; mu2 <- 1; sd2 <- 0.5; curve(0.5*dnorm(x, mean=mu1, sd=sd1) + 0.5*dnorm(x, mean=mu2, sd=sd2),-6,6);
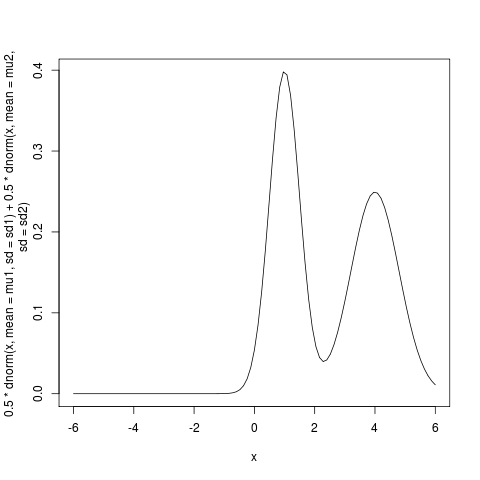
and want to approximate it with a simpler distribution 
We can choose to minimize either 

- minimizing
- minimizing
results in matching moments (our approximating distribution will have the same mean and variance as the mixture, so will be more spread out than either of the two peaks in the true distributions).
In the first case, the approximating density
In the second case, the expectation is taken under the target density
(Once again David MacKay’s wonderful ITILA book has some interesting material related to this; Chapter 33 on variational free energy minimization.)
I wanted to try this optimization out. The KL divergence between two Gaussians has a closed form but it seems this is not the case for mixtures of Gaussians. So let’s fake it by sampling our densities and using discrete distributions:
xx <- -1000:1000/100; p <- dmog(xx,4,0.8,1,0.5); dmog <- function(x, mu1, sd1, mu2, sd2) { 0.5*dnorm(x, mean=mu1, sd=sd1) + 0.5*dnorm(x, mean=mu2, sd=sd2); } kl.div <- function(p, q) { p %*% log(p/q); } dkl.pq <- function(pars) { q <- dnorm(xx, mean=pars[1], sd=pars[2]); kl.div(p, q); } dkl.qp <- function(pars) { q <- dnorm(xx, mean=pars[1], sd=pars[2]); kl.div(q, p); } init <- c(0,2); result.qp <- optim(init, dkl.qp); result.pq <- optim(init, dkl.pq); plot(xx, p, type="l", col="red", ylim=c(0,1)); curve(dnorm(x, mean=result.qp$par[1], sd=result.qp$par[2]), -10,10,col="blue",add=T) curve(dnorm(x, mean=result.pq$par[1], sd=result.pq$par[2]), -10,10,col="green",add=T) result.qp result.pq

We get the expected result:
- the green curve is the minimum
- the blue curve is the minimum
fit, which here approximately fits the mean and sd of one of the two mixture components (
,
). It’s a bit more touchy though, and depends on the initial conditions now.
UPDATE:
After I posted this Iain Murray linked to some nice further material on Twitter:
- This note describing in more detail when the “
- A set of video lectures by David MacKay to accompany the ITILA book
In particular Lecture 14, on approximating distributions by variational free energy minimization, covers much of this material.
It also sets the mathematical scene for what I’m intending to talk about next: Karl Friston’s Free Energy Principle, which applies extensions of these ideas to understanding the brain and behaviour.

Hi. Nice blog, but what happened with Free Energy? I was interested in hearing your take on it.
Life got in the way of good intentions for my free energy blog, I must get on with it. I see you have written some posts on the subject, I’ll have a look. Thanks!